1、首先在windows10打开cmd,选择一个虚拟环境,进入到该虚拟环境中,用命令pip install pdfminer3k下载解析库,如下图所示:
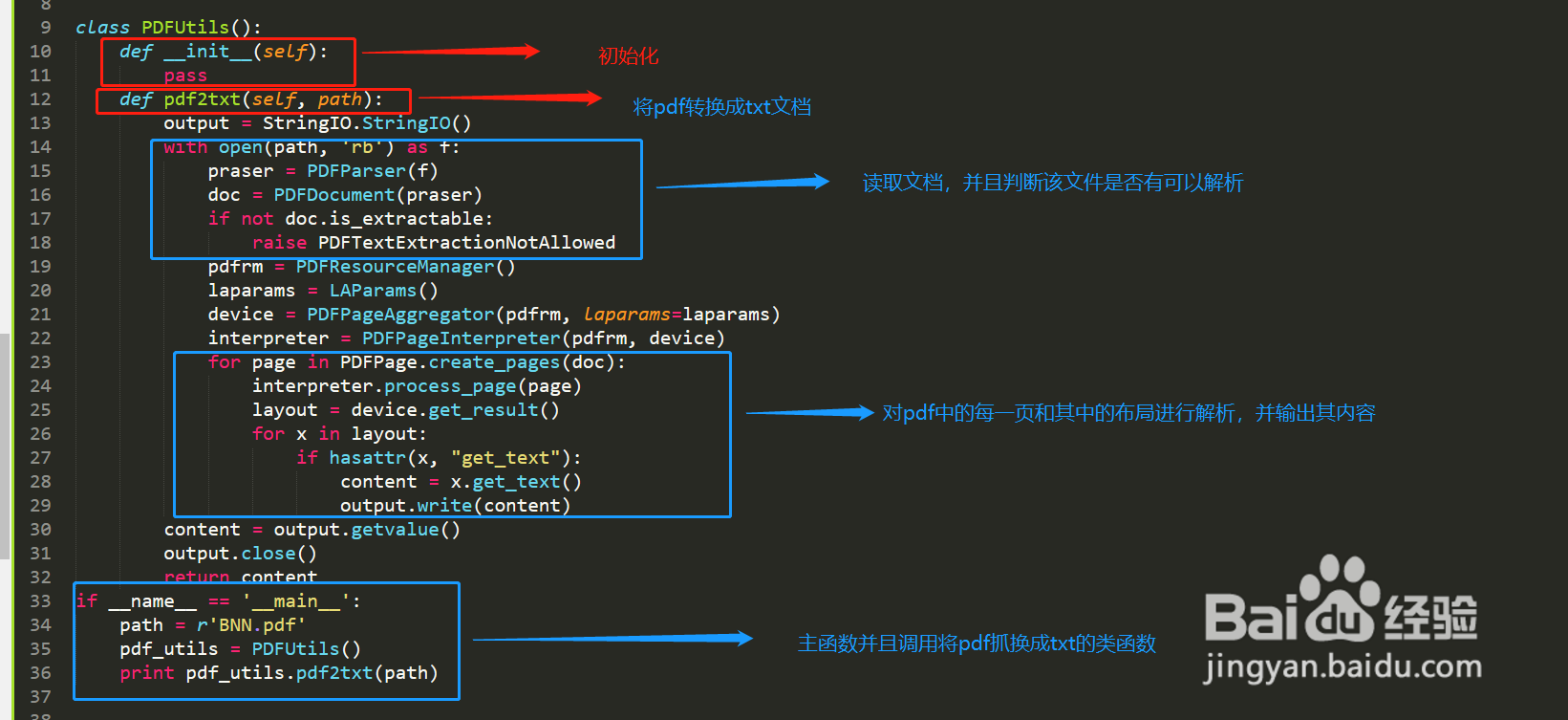
3、对于日常的python编程更倾向于用类把功能进行封装,如下图所示,是将pdf进行解析成txt类的详细讲解。
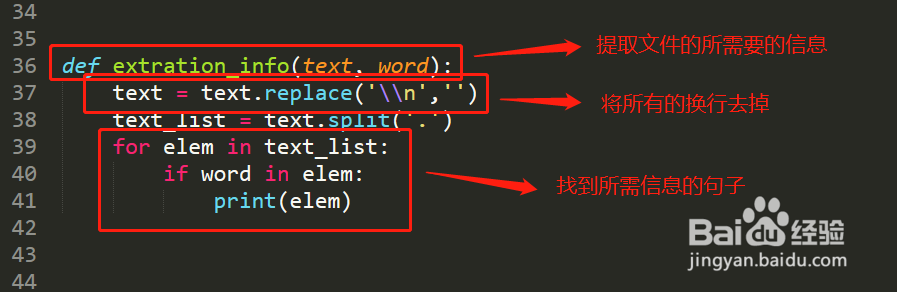
5、pdf文档转换成byte字符流,需要先把byte转换成str字符流,接着对文本进行处理,根据所需要的信息进行提取。
7、在所有的pdf文件中查找单词'also',运行刚才的程序,会有如下所示,可以发现共输出了158个结果,并且每一个结果里都有'also'这个单词的那句话。
9、解析处理pdf文件并提取信息需要一系列复杂操作,先是要进入到程序所在的位置,然后激活虚拟环境,接着需要传参,可以直接用bat一家操作全部完成,非常方便快捷。